#📋 项目详细介绍
1. 项目背景
问题发现
在信息爆炸的时代,用户面临以下痛点:
- ▸📝 内容冗余: 许多文章包含过多修饰词、重复表述和不必要的背景说明
- ▸⏱️ 时间浪费: 手动编辑和精简文本耗费大量时间
- ▸📊 表达效率低: 传统写作风格不适合现代快节奏的信息消费
- ▸💡 缺乏工具: 没有专门的AI工具来帮助内容优化
解决方案
TextSlimmer 应运而生:
- ▸🤖 利用大语言模型(LLM)自动分析和优化文本
- ▸📱 采用"短信写作风格"(短、直、真、有逻辑)
- ▸⚡ 一键快速处理,支持多个优化模型
- ▸🌐 Web应用形式,开箱即用,无需安装
2. 核心功能
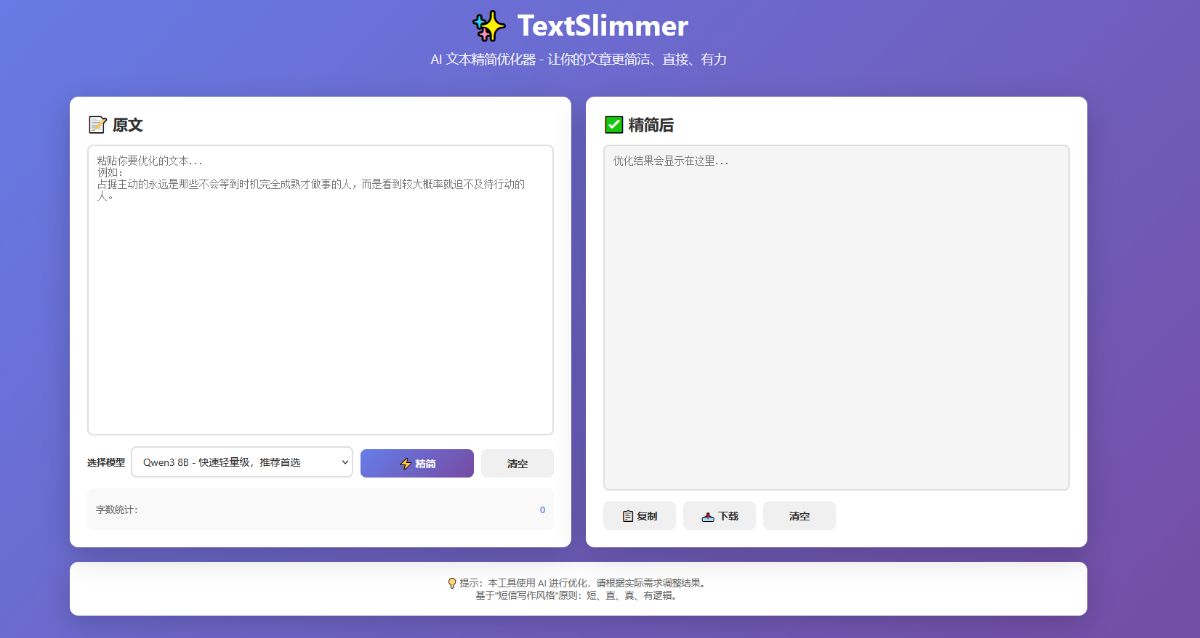
2.1 文本精简优化
【输入】占据主动的永远是那些不会等到时机完全成熟才做事的人,而是看到较大概率就迫不及待行动的人。
【输出】成功者不等时机完全成熟就行动。
优化原则:
- ▸✂️ 一句话一个意思 - 拆分过长句子
- ▸🎯 直接进入观点 - 删除冗长前置和背景
- ▸🧹 删除虚饰 - 移除不必要的副词、形容词、修饰词
- ▸🔗 保留逻辑 - 不过度删除,保持原意
- ▸💬 自然直接 - 语气像在和聪明人对话
2.2 多模型支持
用户可选择不同的AI模型,根据需求平衡速度和质量:
| 模型 | 特点 | 适用场景 | | ------------------ | ---------- | ------------------ | | Qwen3 8B | 快速轻量级 | 日常文本、新闻摘要 | | Hunyuan 7B | 性能均衡 | 通用文本优化 | | GLM-4.1V 9B | 多模态理解 | 复杂文本分析 | | DeepSeek R1 8B | 推理能力强 | 学术论文、专业文章 |
2.3 数据统计
- ▸📊 实时显示原文/优化后字数
- ▸📈 精简比例和减少字符数量
- ▸💾 支持复制和下载功能
2.4 用户体验
- ▸⚙️ 模型下拉框选择,一目了然
- ▸📡 实时进度条显示(0-100%)
- ▸✅ 成功/错误提示消息
- ▸🖥️ 响应式设计,支持PC/Mobile
3. 技术实现
3.1 技术栈详细
前端:
- ▸HTML5 + CSS3(渐变、动画、响应式)
- ▸Vanilla JavaScript(无框架依赖)
- ▸特性:Flex布局、CSS动画、Fetch API
后端:
- ▸Node.js 22.x
- ▸Express.js 4.18.2
- ▸CORS 跨域支持
- ▸dotenv 环境变量管理
部署:
- ▸Vercel Serverless Functions
- ▸GitHub 版本控制
- ▸自动CI/CD流程
API集成:
- ▸SiliconFlow API(国内LLM服务)
- ▸Axios HTTP客户端
- ▸支持4种不同的AI模型
4. 商业化历程
潜在商业化方向
- ▸
SaaS订阅模式
- ▸免费层:每天5次优化
- ▸Pro层:月费$9.99,无限次数
- ▸Enterprise层:企业定制
- ▸
API接口服务
- ▸为其他应用提供文本优化API
- ▸按调用次数计费
- ▸
浏览器插件
- ▸Chrome/Firefox插件
- ▸在任何网页上一键优化
- ▸
企业版本
- ▸本地部署版本
- ▸支持自定义优化规则
- ▸批量处理功能
5. 关键经验与教训
5.1 技术选型
✅ 正确决策:
- ▸选择Express.js: 轻量级、高效、社区支持好
- ▸使用SiliconFlow: 国内API,低延迟、成本低
- ▸部署在Vercel: 自动扩展、易于维护
5.2 用户体验
✅ 成功的设计:
- ▸进度条视觉反馈(解决用户不知道系统在工作的问题)
- ▸模型选择下拉框(简化选择过程)
- ▸实时字数统计(让优化效果可视化)
- ▸清晰的错误提示(帮助用户诊断问题)
❌ 可以改进的地方:
- ▸批量文件上传处理
- ▸离线模式支持
- ▸高级定制优化规则
6. 未来规划
短期(1-3个月)
- ▸[ ] 集成更多高质量模型
- ▸[ ] 添加文本对比功能
- ▸[ ] 支持批量处理
- ▸[ ] 用户账户系统
中期(3-6个月)
- ▸[ ] 浏览器插件开发
- ▸[ ] 移动应用(iOS/Android)
- ▸[ ] 支持更多语言(英文、日文等)
- ▸[ ] API接口开放
长期(6-12个月)
- ▸[ ] SaaS商业化
- ▸[ ] 企业版功能
- ▸[ ] AI训练定制模型
- ▸[ ] 内容创作者社区